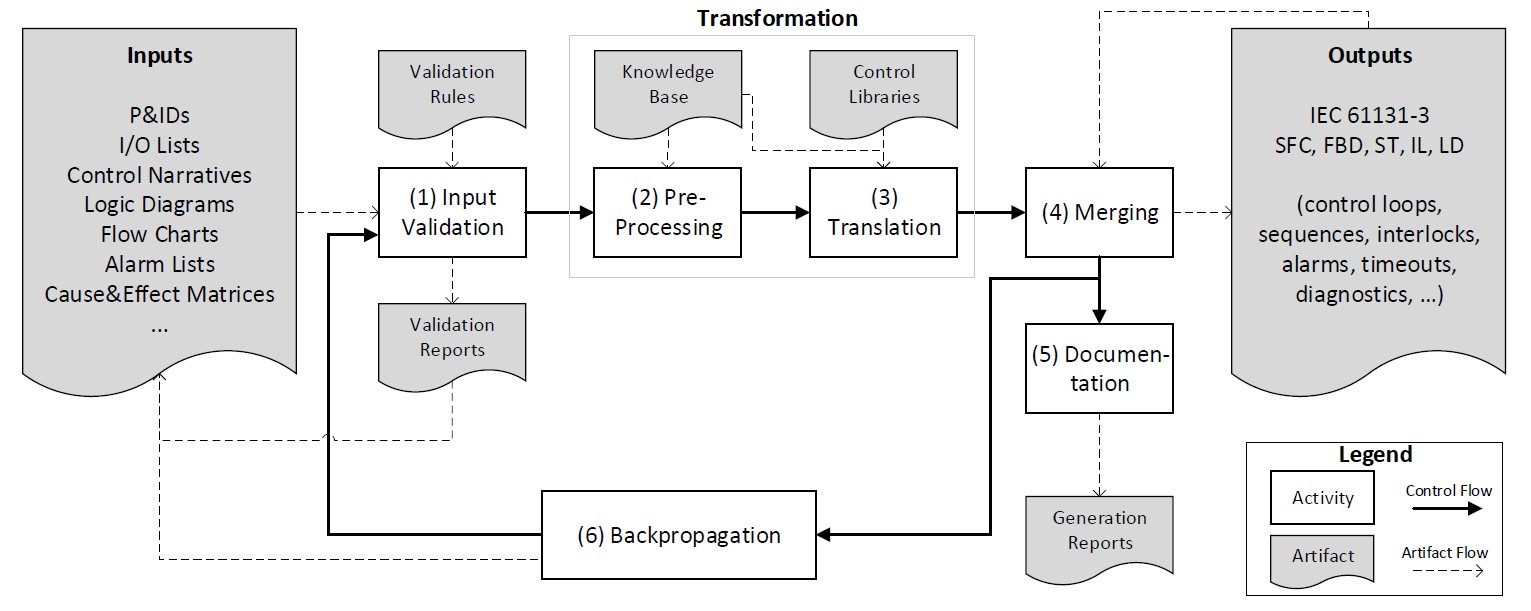
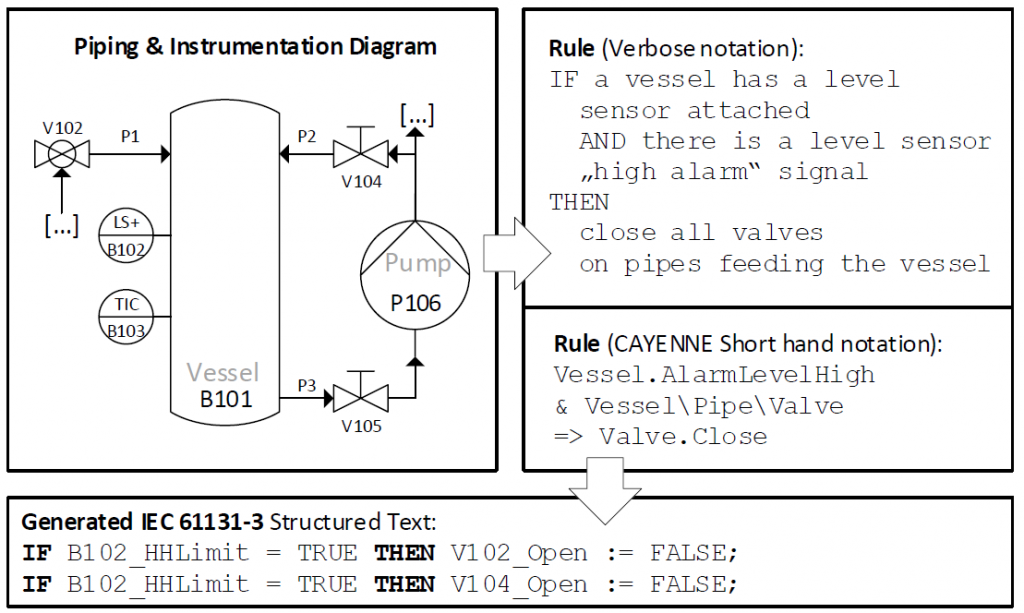
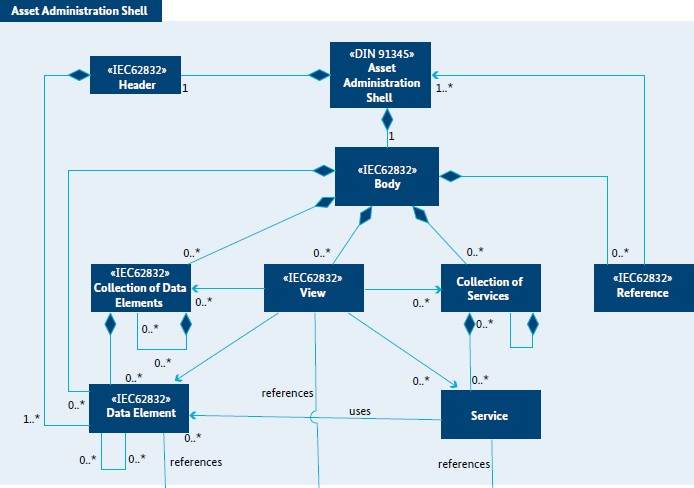
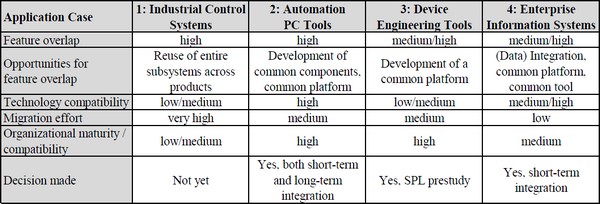
New survey accepted today at Elsevier JSS: Software development for the automation of industrial facilities (e.g., oil platforms, chemical plants, power plants, etc.) involves implementing control logic, often in IEC 61131-3 programming languages. Developing safe and efficient program code is expensive and today still requires substantial manual effort. Researchers have thus proposed numerous approaches for automatic control logic generation in the last two decades, but a systematic, in-depth analysis of their capabilities and assumptions is missing. This paper introduces a novel classification framework for control logic generation approaches, which is applied to analyze 13 different control logic generation approaches. Prominent findings include different categories of control logic generation approaches, the challenge of dealing with iterative engineering processes, and the need for more experimental validations in larger case studies. [Download preprint]